It's been just over four years since we founded EdgeDB Inc. During this time, we've put in hard but fulfilling work, released three major versions of our database, and today we're shipping the fourth. What else is shipping? EdgeDB Cloud!
We’re kicking off this launch with a keynote presentation. Alongside discussing EdgeDB 4.0 and the Cloud, we’ve invited four amazing engineers and founders to share their stories about building real-world products with EdgeDB. Tune in, or, if you prefer to read, read on!
Before we dive in, let’s quickly catch up any new readers who might not yet be familiar with EdgeDB. It’s a new database that comes with a strictly typed, declarative schema. Its query language blends the best of GraphQL and SQL. It has a built-in migrations engine and is based on PostgreSQL. Plus, it’s fully open-source. That’s just scratching the surface of what EdgeDB can offer. The bottom line? It’s a database that combines great developer experience, strict typing, and performance, designed to make both you and your backend fly.
EdgeDB Cloud
At EdgeDB, we are proud of our thorough vertical integration. EdgeDB is a rare breed among relational databases. It fully owns its data model, query language, tooling, protocols, and client bindings and APIs. Because of this, we’ve been optimizing EdgeDB for cloud efficiency since day one — years before today’s launch — giving our cloud product a number of important competitive advantages.
Performance advantage
The biggest performance advantage of EdgeDB comes from its query language, EdgeQL. From the start, our goal was to enable both convenient and virtually limitless composability in the language. Take this as an example for rendering a screen in a hypothetical movie catalog app:
select {
current_user := (
select User {
name,
number_of_reviews := count(.reviews),
reviews: {
body,
rating,
movie: {
title,
}
},
} filter .id = <uuid>$user_id
),
current_movie := (
select Movie {
title,
year,
cast: {
name
}
}
) filter .id = <uuid>$movie_id
}const query = e.params(
{user_id: e.uuid, movie_id: e.uuid}, (user_id, movie_id) =>
e.select({
current_user: e.select(e.User, (user) => ({
name: true,
number_of_reviews: e.select(e.count(user.reviews)),
reviews: {
body: true,
rating: true,
movie: {
title: true,
}
},
filter e.op(user.id, '=', user_id)
})),
current_movie: e.select(e.Movie, (movie) => ({
title: true,
year: true,
cast: {
name: true
},
filter: e.op(movie.id, '=', movie_id)
}))
})
);
const result = await query.run(client, {
user_id: ...,
movie_id: ...
}); // fully typedThis query pulls all the necessary data in one shot: just one roundtrip between the database and the backend, and one atomic query inside the database. Plus, if you use our codegen or TypeScript query builder, you get full end-to-end type safety in your code for free.
So, how does this all connect to cloud performance? Each extra database query means an additional roundtrip between the database and your backend. When you write idiomatic SQL by hand or use typical ORM libraries, you (often inadvertently) end up making multiple queries for just one screen of your app or a single API handler. This leads to a host of issues, with poor performance being just the tip of the iceberg. The challenges are even greater in cloud deployments, where latency simply skyrockets.
With EdgeDB you can conveniently have just one query per endpoint, drastically reducing the overall latency of serving a request.
Operational advantage
EdgeDB Cloud gains operational advantages from our specialized network protocol and client APIs. Here’s how:
-
The protocol is stateless and fine-tuned for speed. It can be tunneled through HTTP, making it a great fit for edge environments.
-
Our client libraries are smart. Every API is carefully designed to automatically reconnect if a network error occurs. If a query was in progress during a disconnect, the library will retry it — provided it’s safe to do so. Same applies to transaction serialization errors – clients will automatically retry failed transactions, which gives you ultimate confidence in data consistency without sacrificing developer or end user experience.
-
Connection pooling is seamlessly implemented and auto-configured by all clients. It just works.
-
EdgeDB speaks GraphQL over HTTP. And it fully supports the PostgreSQL wire protocol. This means you can connect any tool that works with PostgreSQL and write analytical SQL queries against your data. All of this happens through the same network endpoint, as EdgeDB auto-negotiates the protocol based on client needs.
-
All communication is secure by default with enforced TLS, and each EdgeDB Cloud instance gets a free trusted TLS certificate.
Last but not least, EdgeDB is built on top of PostgreSQL, one of the most trusted and proven database solutions of our time.
Developer experience advantage
DX is paramount and has been our top focus since we first started building EdgeDB.
Firstly, in the age of cloud databases, the convenience of local development
is often overlooked. Users have to figure out on their own how to install and
configure a database for development, which can be particularly challenging
if they want to test multiple versions at the same time.
With EdgeDB it takes just one curl command to install:
curl -sSf https://sh.edgedb.com | shThe edgedb command is a Swiss Army knife that allows you to create new
databases, create and apply schema migrations, launch the built-in graphical
UI, and do a vast array of other things.
Secondly, EdgeDB reduces the amount of configuration for development instances to near zero. It transparently handles creating TLS certificates, finding an available network port, stopping the database when not in use and starting it up again, and figuring out the connection options.
Naturally, we wanted EdgeDB Cloud to follow the same principles. Run edgedb
cloud login to authenticate with GitHub, and you can now create a database in
the cloud right from your terminal. If you prefer, use the graphical UI…
speaking of which:
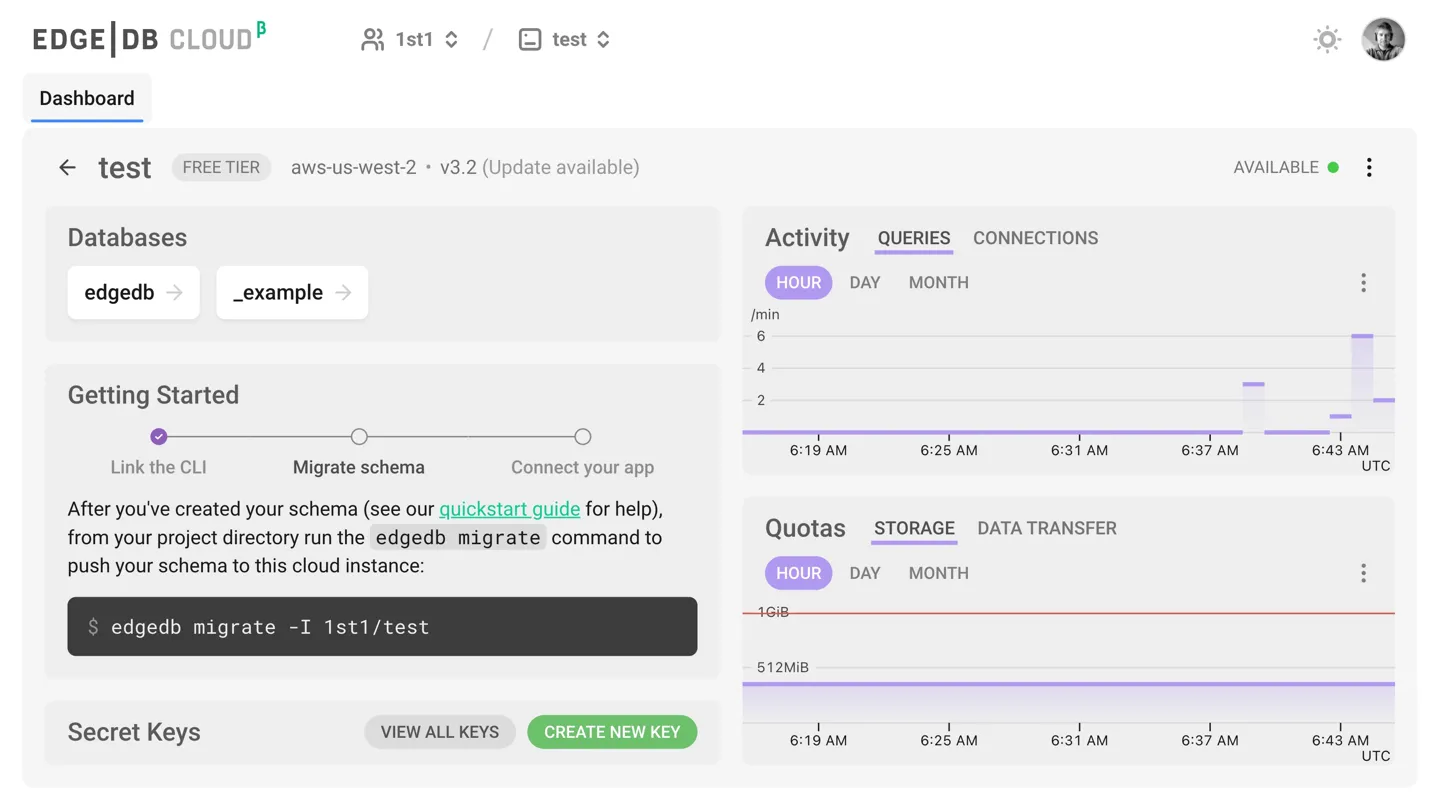
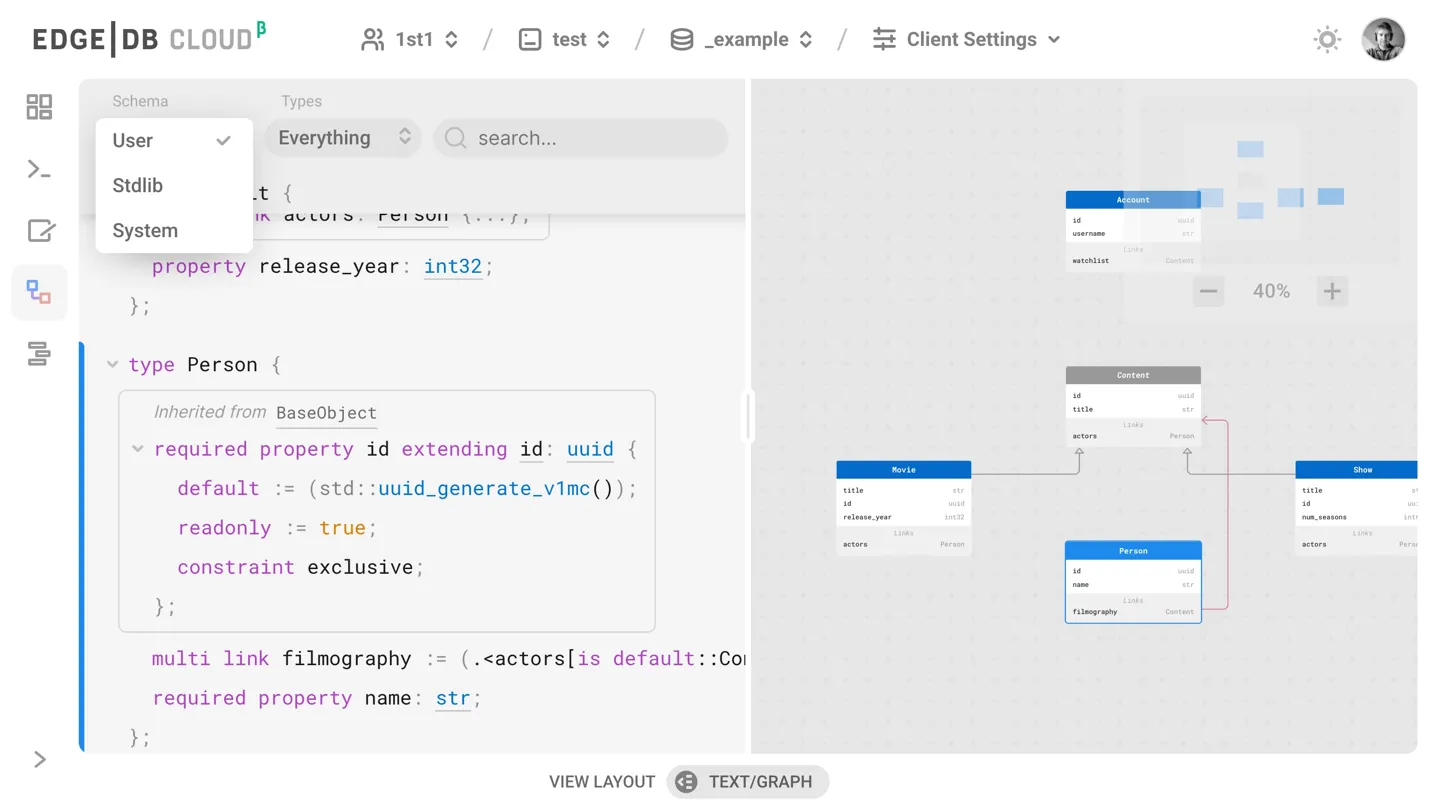
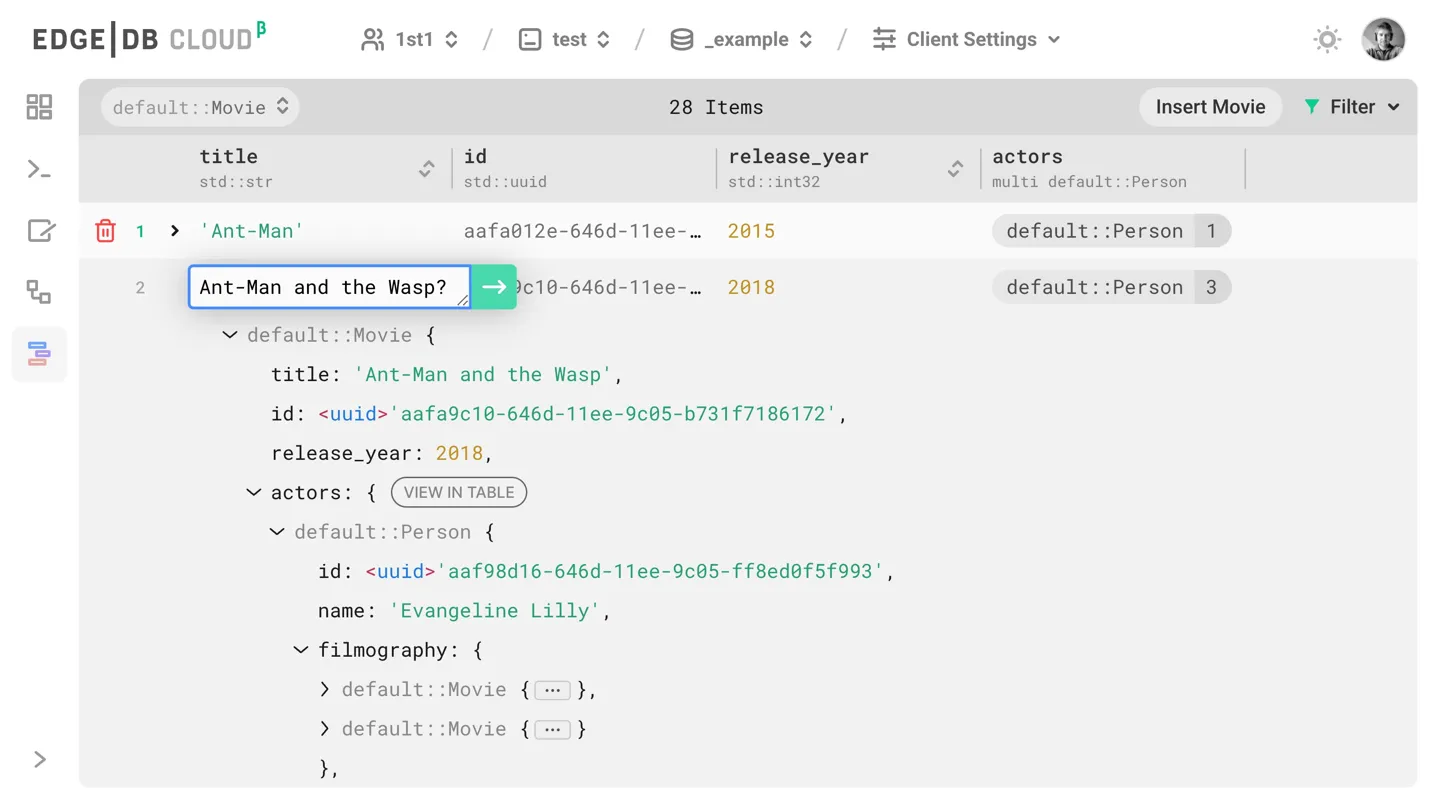
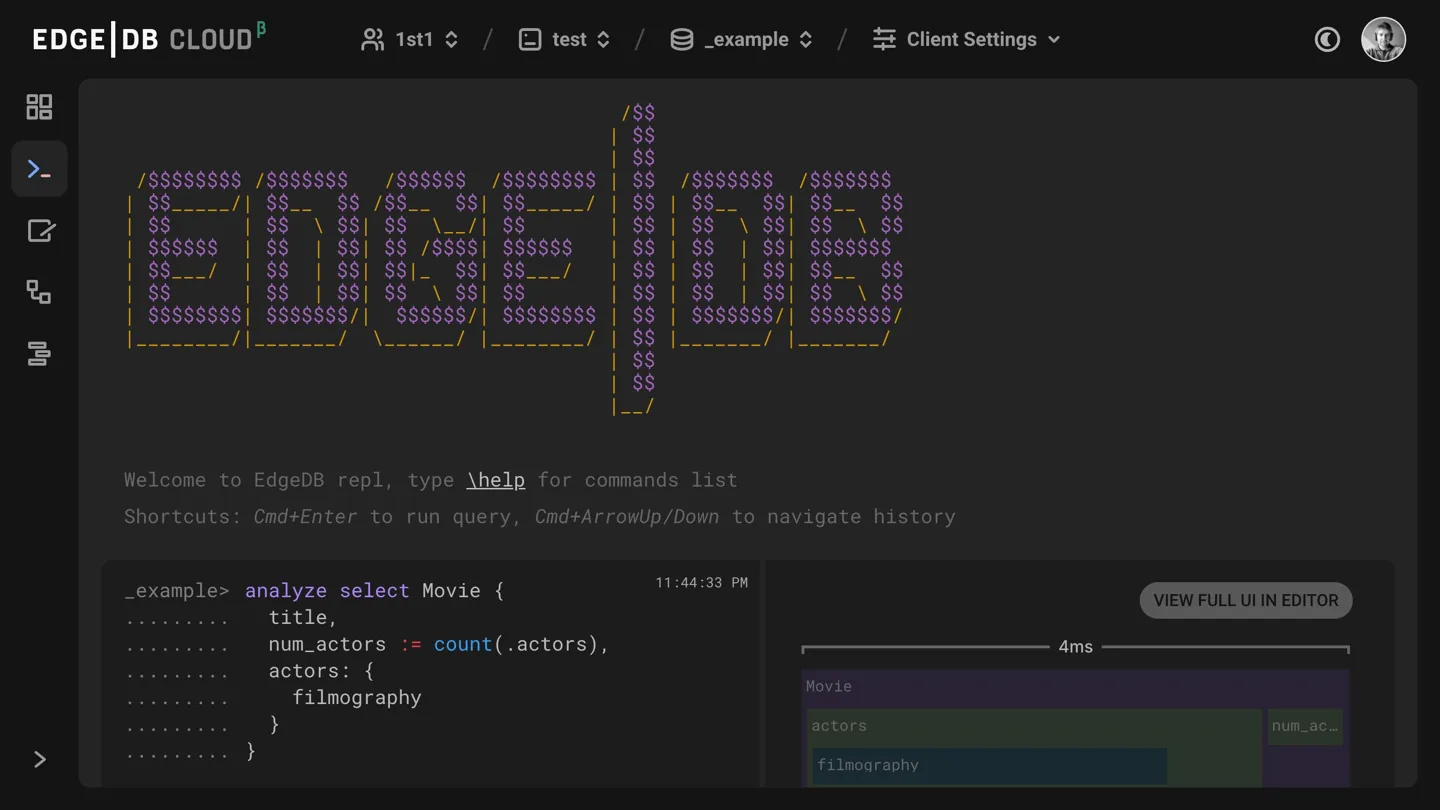
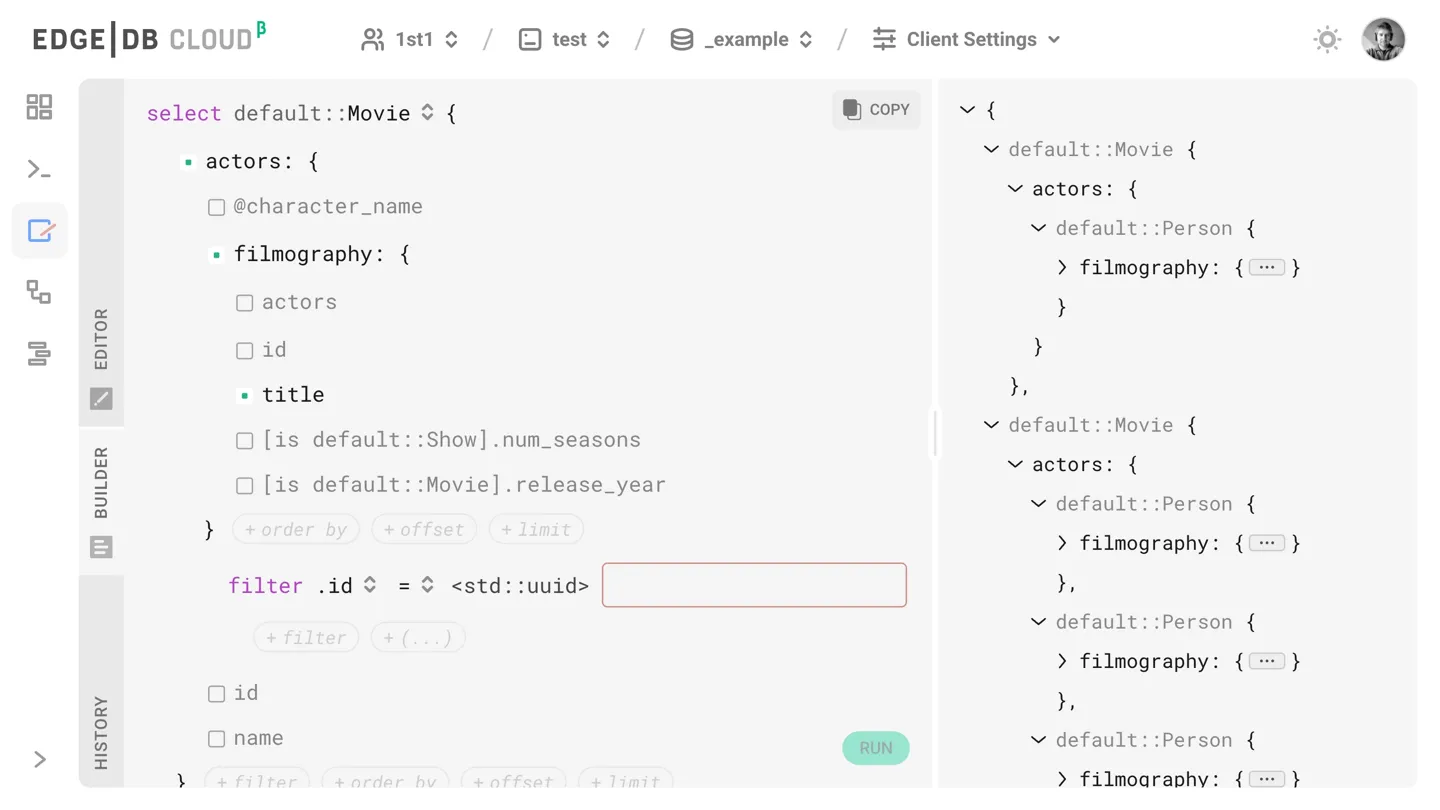
Cloud name resolution is automatic in command line tools and client APIs.
EdgeDB Cloud database names follow the GITHUB_ORG/DB_NAME format
(Github repo style).
E.g. if I want to explore my “test” cloud database, I’d just run
edgedb ui -I 1st1/test. Everything is cross-integrated and clicks together.
The future of EdgeDB Cloud
EdgeDB Cloud is here and ready for you to build on, but that doesn’t mean we’re calling it “done.”
We plan to continuously evolve the product and ship updates on a regular basis, with a number of performance and usability improvements already setting sail. We’ll also be launching our free tier soon.
Our vision for EdgeDB Cloud is grand. We want to build a fast, reliable, and, most importantly, enjoyable data platform. One that offers a frictionless alternative for building apps and services at any scale, from a weekend hackathon app to a SaaS powering Fortune 500 companies. We have the technology and ambition to build it and we invite you to join us on this journey.
Now it’s time to talk about the all new EdgeDB 4!
EdgeDB 4
EdgeDB 4 is here with some nifty new stuff in it:
-
Full text search support
-
Integrated auth solution
-
More powerful “if” expression
-
Multi-ranges
-
and many other smaller features and fixes.
FTS
The flagship new language feature in 4.0 is full text search, which of course we refer to using its three-letter acronym: FTS. I’d take a short snippet of code rather than a thousand words, so there it is:
type Item {
required name: str;
description: str;
index fts::index on (
fts::with_options(
.name,
language := fts::Language.eng,
),
);
}type Item {
required name: str;
description: str;
index fts::index on (
fts::with_options(
.name,
language := fts::Language.eng,
),
fts::with_options(
.description,
language := fts::Language.eng,
),
);
}type Item {
required name: str;
description: str;
index fts::index on (
fts::with_options(
.name,
language := fts::Language.eng,
weight_category := fts::Weight.A,
),
fts::with_options(
.description,
language := fts::Language.eng,
weight_category := fts::Weight.B,
)
);
}Once the index is in the schema, using it is trivial with the new
fts::search() function:
db> ...
select fts::search(
Item, 'candy corn', language := 'eng');{
(
object := default::Item {id: 9da06b18...},
score := 0.30396354,
),
(
object := default::Item {id: 92375624...},
score := 0.6079271,
),
}db> ... ... ... ... ... ... ... ...
with result := (
select fts::search(
Item, 'candy corn', language := 'eng')
)
select result.object {
name,
score := result.score
}
order by result.score desc;{
default::Item {name: 'Candy corn', score: 0.6079271},
default::Item {name: 'Canned corn', score: 0.30396354},
}db> ... ... ... ... ... ... ... ... ...
with result := (
select fts::search(
Item, 'sweet AND "treat made" AND !salt',
language := 'eng',
)
)
select result.object {
name, description, score := result.score
}
order by result.score desc;{
default::Item {
name: 'Sweet',
description: 'Treat made with corn sugar',
score: 0.70076555,
},
}db> ... ... ... ... ... ... ... ... ... ...
with result := (
select fts::search(
Item, 'corn treat',
language := 'eng',
weights := [0.2, 1],
)
)
select result.object {
name, description, score := result.score
}
order by result.score desc;{
default::Item {
name: 'Sweet',
description: 'Treat made with corn sugar',
score: 0.6079271,
},
default::Item {
name: 'Candy corn',
description: 'A great Halloween treat',
score: 0.36475626,
},
default::Item {
name: 'Canned corn',
description: {},
score: 0.06079271,
},
}We’re big fans of the new FTS. Perhaps its most interesting aspect is the design of the API. It’s built to be flexible, playing nicely not just with the built-in PostgreSQL FTS, but also with external engines like Elastic. The grand vision? Down the line, you’ll be able to configure your production deployment to use an external search engine seamlessly. Everything should just work, no hassle. You can start using built-in Postgres FTS today with 4.0, but in the future, the sky is the limit for EdgeDB’s FTS!
For more details on the current implementation of FTS and what’s to come soon, check out the RFC!
Integrated auth
Let’s be honest. Getting authentication to just work most of the time might
be the hardest part of computer science web development.
The process is filled with repetitive, dull tasks: confirming email addresses, navigating OAuth, juggling JWTs—the list goes on. While using a third-party service is a viable approach, it’s not the only way to go. Your database already holds some user data, and EdgeDB has had built-in access policies since version 2. So, it made perfect sense for us to roll out authentication as a native EdgeDB extension. You can take advantage of email/password authentication or OAuth authentication with Apple, Azure (Microsoft), GitHub, or Google, all with very minimal configuration.
Enable it by simply dropping one line in your schema:
using extension auth;Once it’s set up, you can configure the extension either through EdgeQL’s
configure commands or via the admin UI. But here’s the kicker: EdgeDB auth
doesn’t just offer an API; it also comes with a built-in login UI that you
can brand to match your app. So, if you don’t want to sink time into crafting
your own UI, you don’t have to. If you do want to build your own, we’ve got
an API to help you build it your way. This can be a real time-saver when you’re
piecing together the first version of your app.
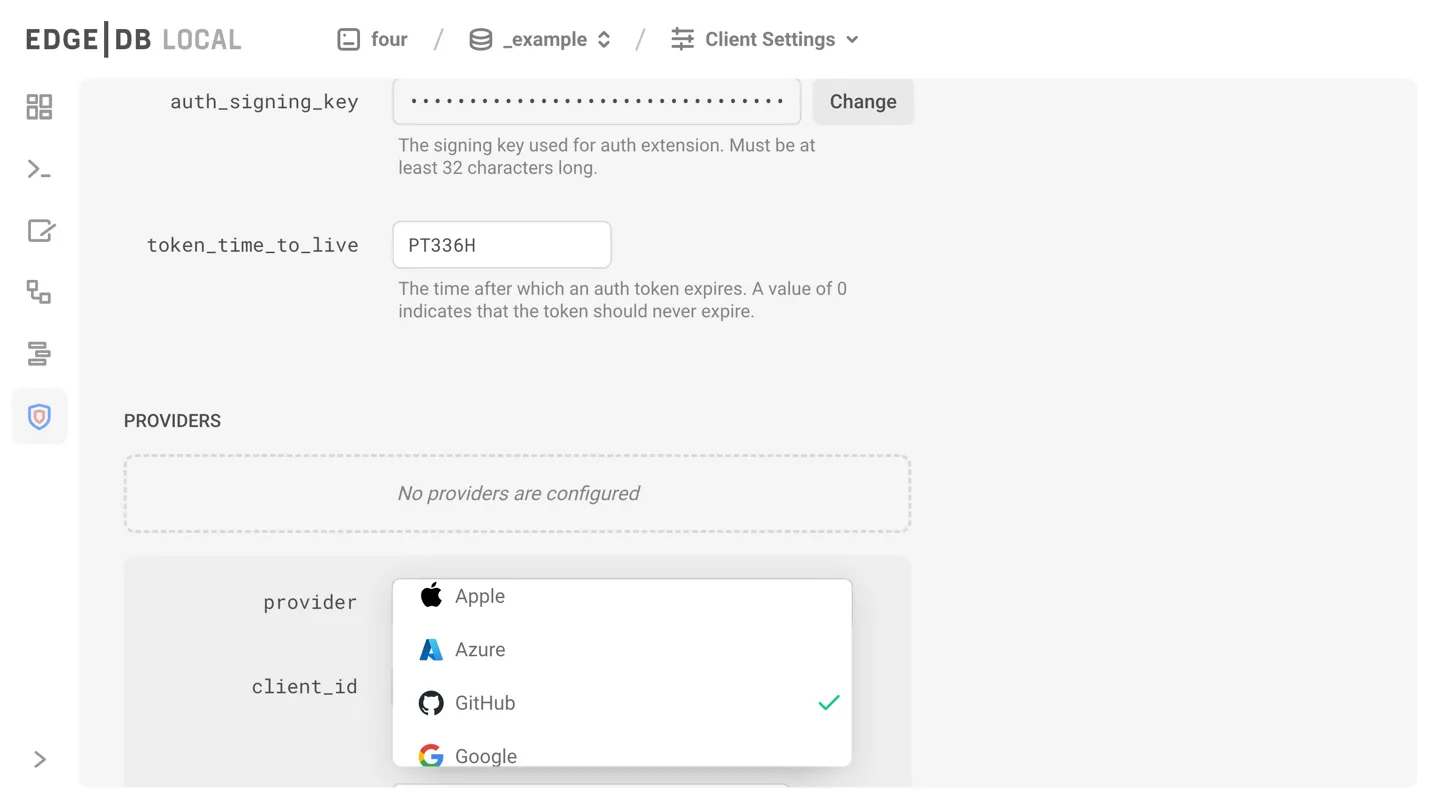
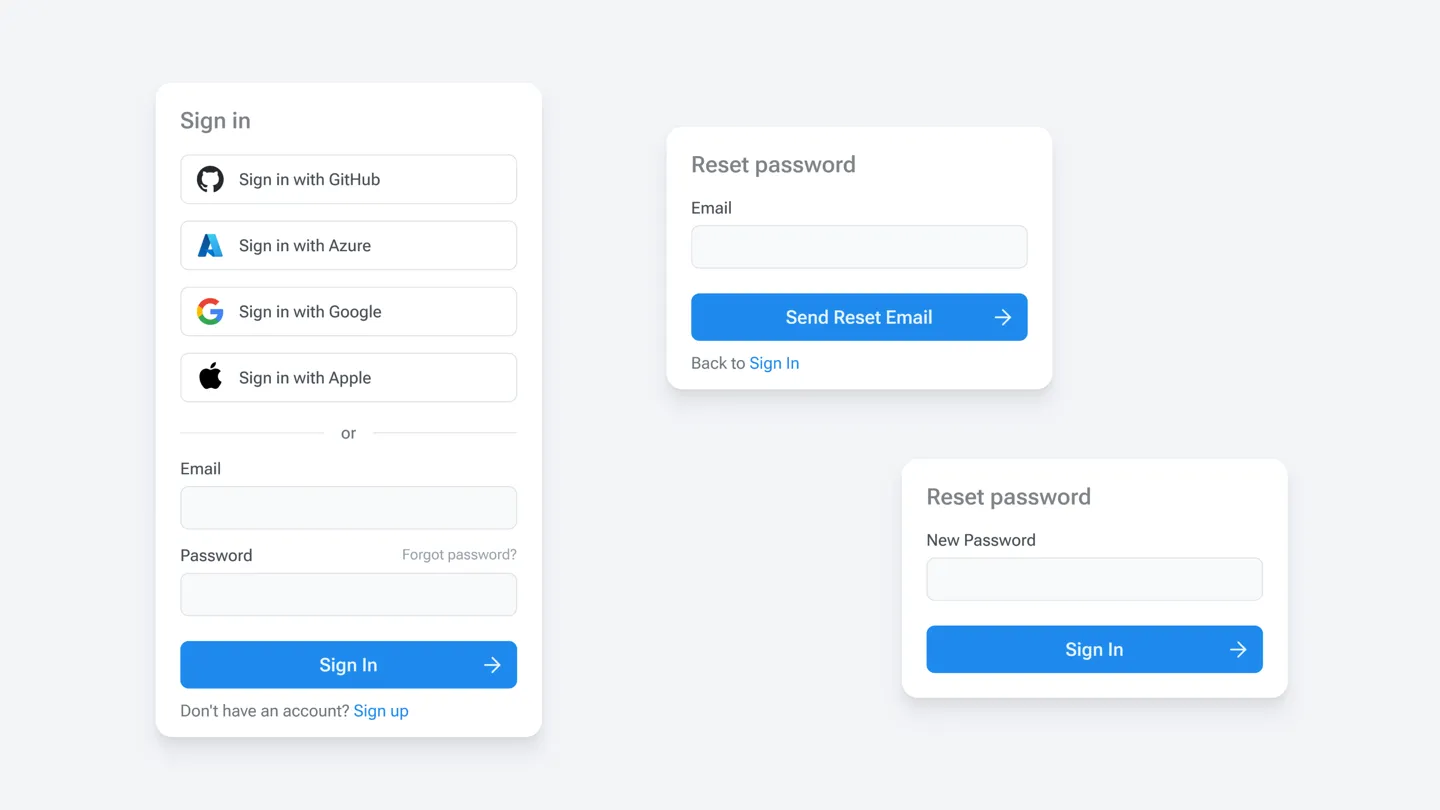
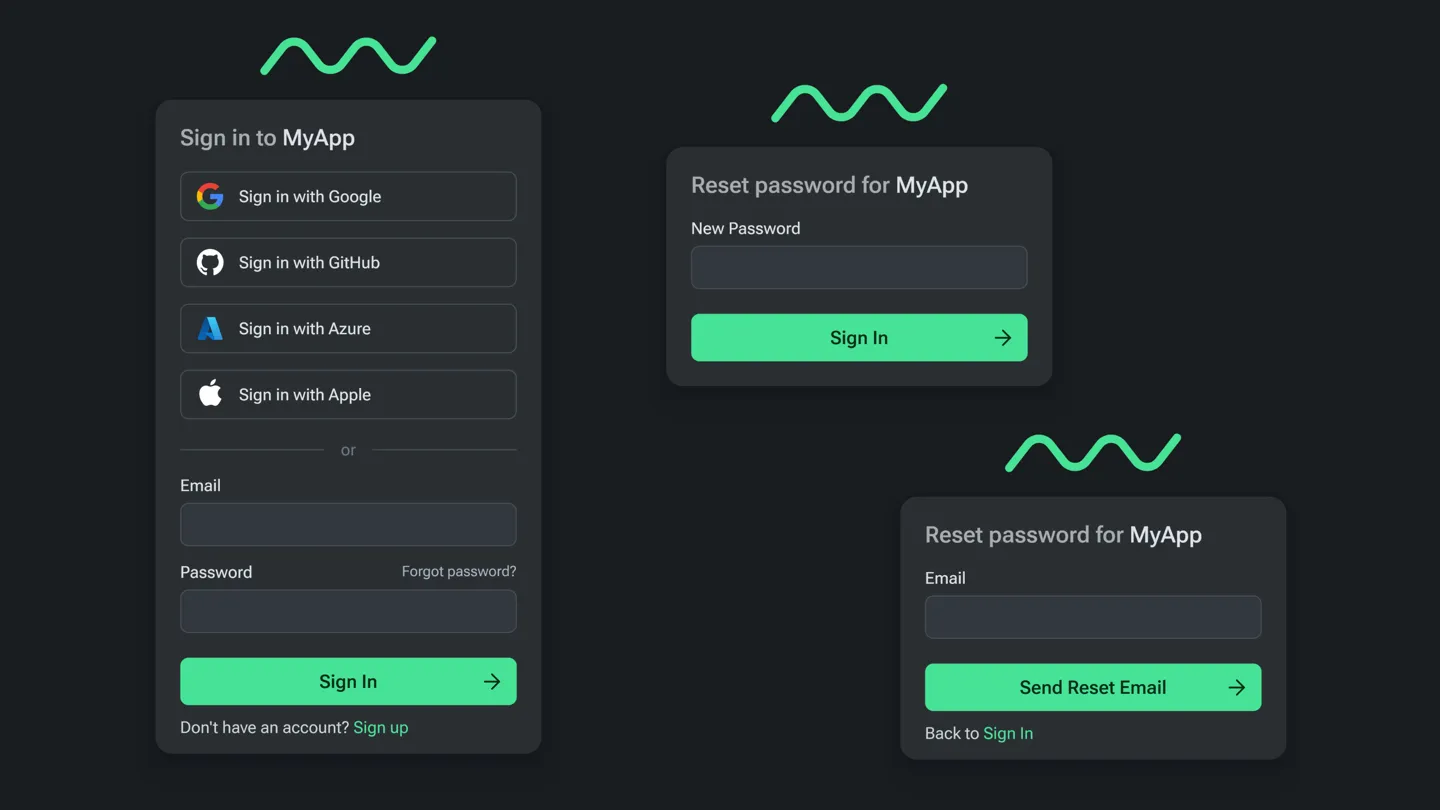
Integrating auth into your backend is pretty straightforward. All you need do is add two one-liners to kick off the proof key for code exchange (PKCE) flow and to handle logged-in or signed-up users. We’re working on libraries that will make this dead simple for popular frameworks. We’re shipping one for NextJS today, followed by one for FastAPI soon.
In terms of schema, the auth extension exposes an Identity type that
you can easily link to your custom User type. It also comes with
built-in globals that you can use in your access policies and EdgeQL
queries.
using extension auth;
global current_user := (
assert_single((
select User
filter .identity =
global ext::auth::ClientTokenIdentity
))
)
type User {
required identity: ext::auth::Identity;
required name: str;
}type Post {
required text: str;
required author: User;
access policy author_full_access
allow all
using (
.author ?= global current_user
);
access policy others_read_only
allow select;
}select (global current_user) {
name,
...
}const authedClient = client.withGlobals({
"ext::auth::client_token": auth_token
});
const query = e.select(e.global.current_user, () => ({
name: true,
…
}));Looking ahead, we’ll be enhancing the auth extension with more OAuth providers (GitLab, Slack, many others), enabling integration with Okta and Auth0, as well as accepting third-party tokens to help integrate into existing or enterprise authentication systems. Eventually, we aim to have EdgeDB auth natively support features like 2-factor authentication, magic links, and emerging standards like WebAuthn to make use of the latest security tech like PassKeys.
Our goal is for our authentication extension to be a one-stop solution, solving authentication challenges for all types of projects, big or small.
Wrapping up
We’re thrilled to launch EdgeDB Cloud and EdgeDB 4 today, and we hope you find them as delightful as we do!
If you’re reading this blog post on November 1st then please join our Discord for a live Q&A. We’d love to chat with you!
And if you want to go ahead and create your first EdgeDB Cloud instance right now, just click here 😉!


